成功的奥秘在于目标的坚定。——迪斯雷利
zookeeper一般的使用场景
分布式一般都会考虑到分布式锁,而zookeeper是用在分布式锁里很常用的。
大致来说,zk的使用场景如下:
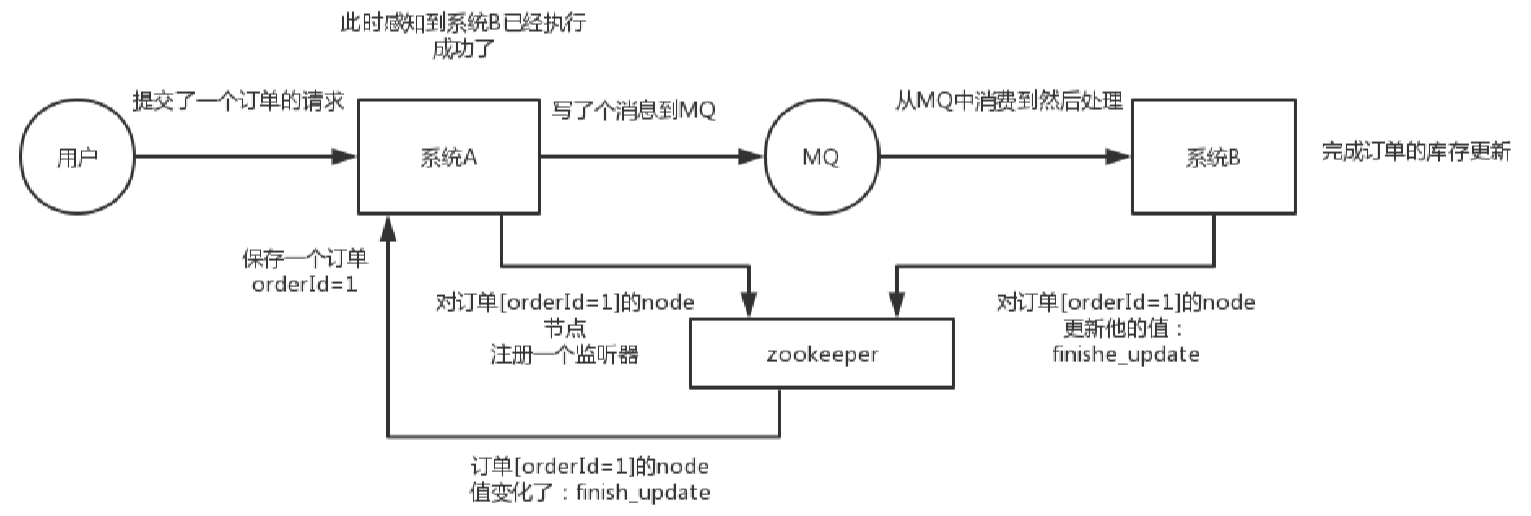
(1)分布式协调:这个其实是zk很经典的一个用法,简单来说,就好比,你A系统发送个请求到mq,然后B消息消费之后处理了。那A系统如何知道B系统的处理结果?用zk就可以实现分布式系统之间的协调工作。A系统发送请求之后可以在zk上对某个节点的值注册个监听器,一旦B系统处理完了就修改zk那个节点的值,A立马就可以收到通知,完美解决。
zookeeper一开始的定位就是做分布式协调。让多个系统协调起来,某个系统要感知另一个系统当前的处理结果和状态。
分布式协调如下图:
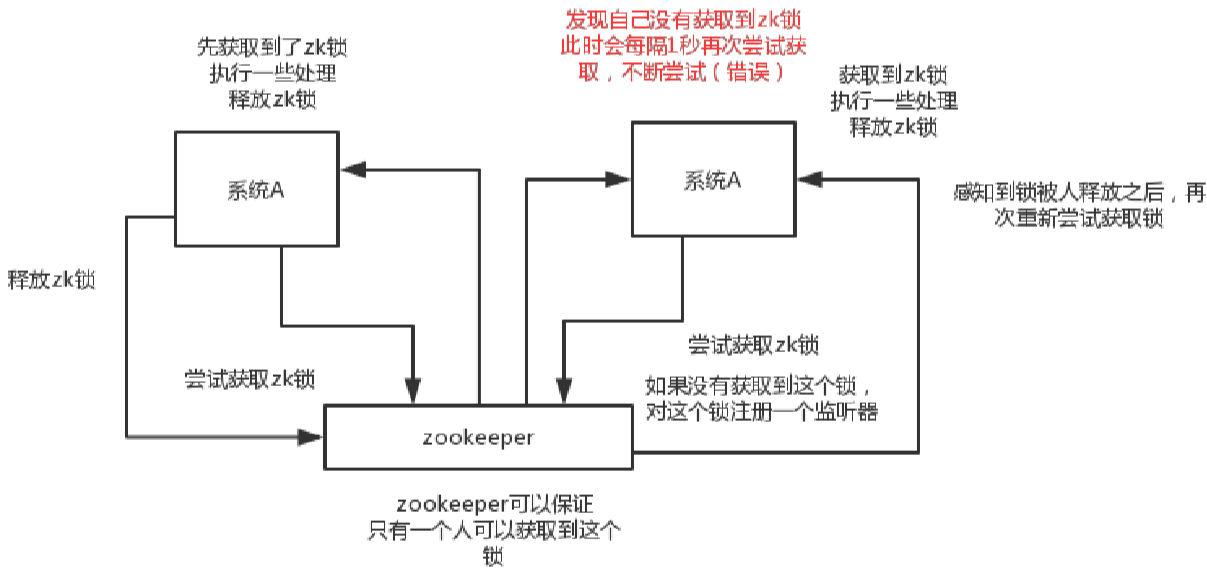
(2)分布式锁:对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行另外一个机器再执行。那么此时就可以使用zk分布式锁,一个机器接收到了请求之后先获取zk上的一把分布式锁,就是可以去创建一个znode,接着执行操作;然后另外一个机器也尝试去创建那个znode,结果发现自己创建不了,因为被别人创建了。。。。那只能等到另一个机器执行完,把锁释放掉,后来的机器才能执行。
分布式锁如下图:
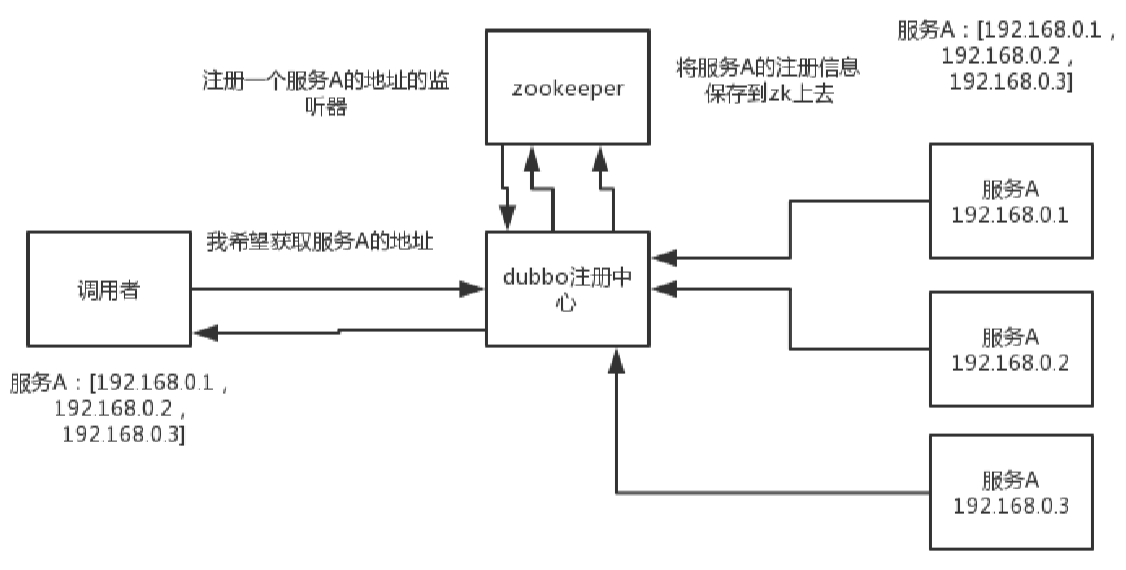
(3)元数据/配置信息管理:zk可以用作很多系统的配置信息的管理,比如kafka、storm等等很多分布式系统都会选用zk来做一些元数据、配置信息的管理,包括dubbo注册中心也支持zk
举例,服务A在三台机器上,这些数据放到了dubbo数据中心,然后dubbo会基于zookeeper的元数据来保存这个配置信息,此后只要数据有了变化,zookeeper会实时监听,并且把更新的数据告诉调用者。
实际上,消息队列Kafka,流式计算引擎Storm,都基于zookeeper的元数据管理。
(4)HA高可用性:就是实现主备系统。这个应该是很常见的,比如hadoop、hdfs、yarn等很多大数据系统,都选择基于zk来开发HA高可用机制,就是一个重要进程一般会做主备两个,主进程挂了立马通过zk感知到切换到备用进程。
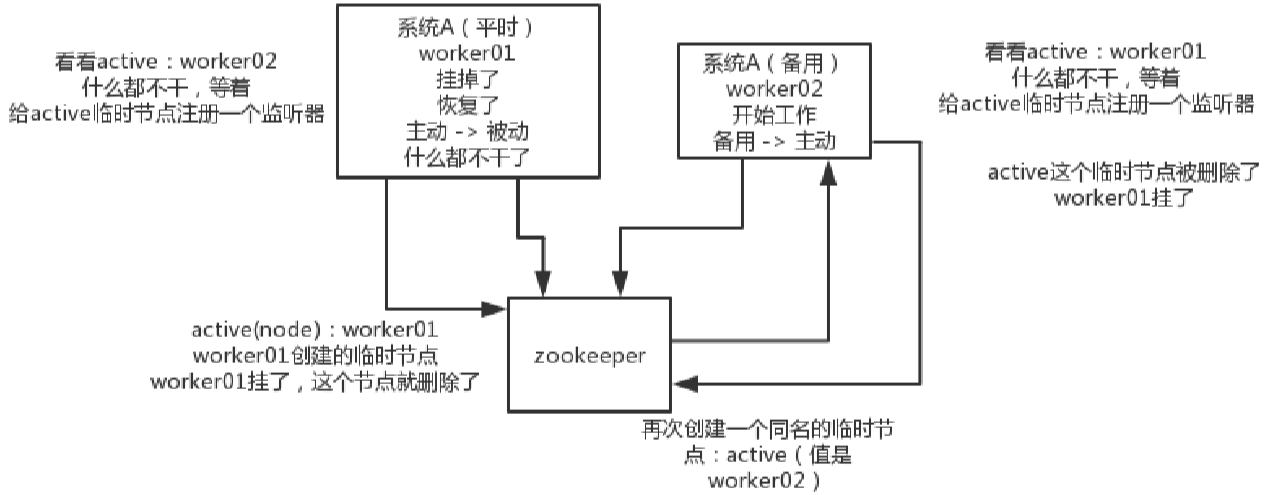
临时节点名字是active,具体可以被设置成active是worker01或者work02。
一开始设置成了worker01,那么只由worker01工作,但是如果worker01挂掉了,那么这个临时节点会被ZK删除掉,然后重新定义一个新的active节点,并且赋值为worker02。
Zookeeper内部原理(面试重点)
Zookeeper选举机制(详细算法参考paxos)
选举机制,即如何选出集群中的Leader(集群中只有一个Leader,其他都是follower)。
1)半数机制:只有集群中半数以上机器存活,集群才能可用。所以zookeeper适合安装奇数台服务器。
举个例子,如果你集群中有5台机器,那么挂掉2台还可以工作,挂掉3台就不行了。如果集群有6台机器,那么挂掉3台也不可以工作了,所以一般建议配成奇数台机器。
2)Zookeeper虽然在配置文件中并没有指定Master和Slave,但是ZK工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内布的选举机制临时产生的。
3)以一个简单的例子说明选举过程
假设现在有五台服务器组成的ZK集群,它们的id从1-5,同时它们都是最新启动的,即没有历史数据,而且每台机器存放的数据量也是一样的。假设这些服务器依序启动,会发生什么?如何选举?
五台机器如下图所示:

一开始,第一台机器Server1启动,会自动投自己一票,但是因为此时节点数量未过半,所以节点1处于Looking状态。后面Server2启动,也会投自己,然后Server1会投给2,因为id最大,但是因为未过半所以还是处于Looking状态。后面类似,后面来的,myid大的,就投票给它。
但是注意,只要Leader选出来了,就是既定事实,不能变了。
所以,当每个机器新加入集群的时候,首先会投票给自己,如果票投给自己选不出来Leader,那么会把它这一票投给id号大的。一旦某个机器得到的选票过半,它就是leader,后面再加入机器,也不能是Leader,因为Leader已经定了。(注意,ZK启动的时候知道有多少台服务器,因为你已经写了数据到ZK的配置文件里了)
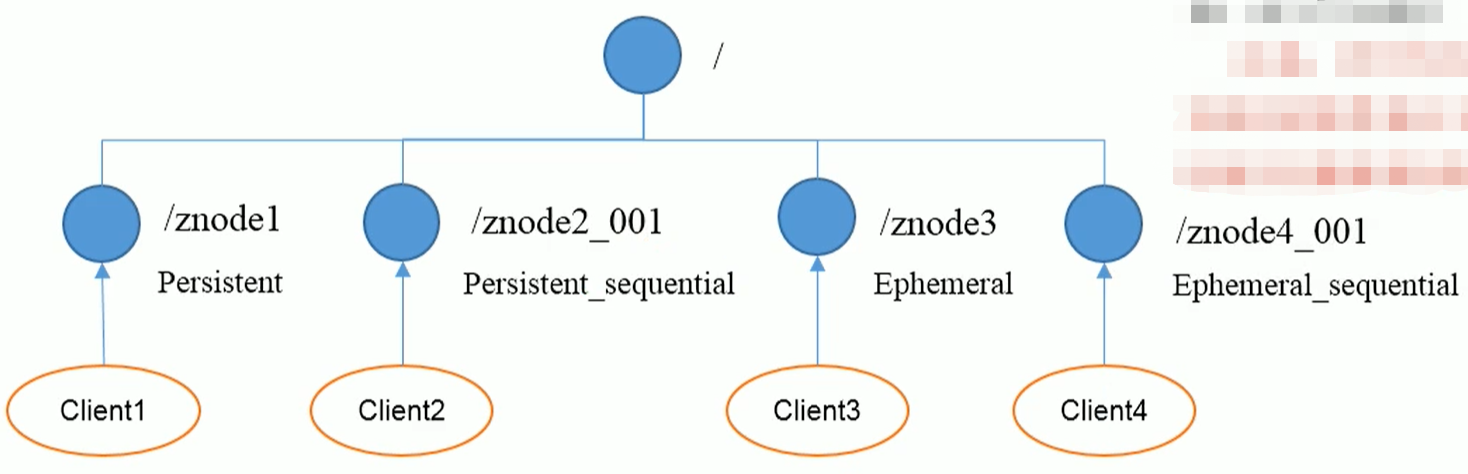
Zookeeper节点类型
一共分为两大类,四种。
持久节点(Persistent):客户端和服务端断开连接后,创建的节点不删除。
持久类节点分为两种:
- 持久化目录节点:客户端与ZK断开连接后,该节点仍然存在
- 持久化顺序编号目录节点:客户端与ZK断开连接后,该节点依旧存在,只是ZK会对该节点名称进行书序编号。
说明:创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。而有顺序号的节点有一个用处:顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序。
临时节点(Ephemeral):客户端和服务端断开连接后,创建的节点会被自己删除。
临时节点也分为两类:
- 临时目录节点:客户端与ZK断开连接后,该节点被删除
- 临时顺序编号目录节点:客户端与ZK断开连接后,该节点被删除,只是ZK给该节点名称进行顺序编号。
为什么有的节点要在断开连接后删除?——有必要,有一些服务器记录的是其他服务器是否在线的数据,所以如果节点断开连接后,删除记录,那么查询的时候查不到数据,说明用户已经下线。
四种类型的节点如下图所示:
Zookeeper监听器原理(详细参考Raft算法)
ZK监听器经常会被用到,因为其用到了观察者模式。
监听器会按照以下步骤工作:
1)创建main()线程
2)在main线程中创建zookeeper客户端对象(主要用于访问server服务器),这时就会创建两个线程,一个负责正常业务通讯,即网络连接通信(connect),一个负责监听(listener)。
3)通过connect线程将注册的监听事件发送给zookeeper
4)在zookeeper注册监听器列表中将注册的监听事件添加到列表中
5)zookeeper监听到有数据或者路径变化,就会回调main()线程,将这个消息发送给listener线程,告诉客户端现在有事情发生,要处理。
6)listener线程内部调用process()方法
如下图所示:

常见监听方式:
1)监听节点数据的变化:get path [watch]
2)监听子节点增减的变化:ls path [watch]