盼望一件事会发生的人祈祷;相信一件事将发生的人专注;让一件事能发生的人行动
分布式系统及相关知识
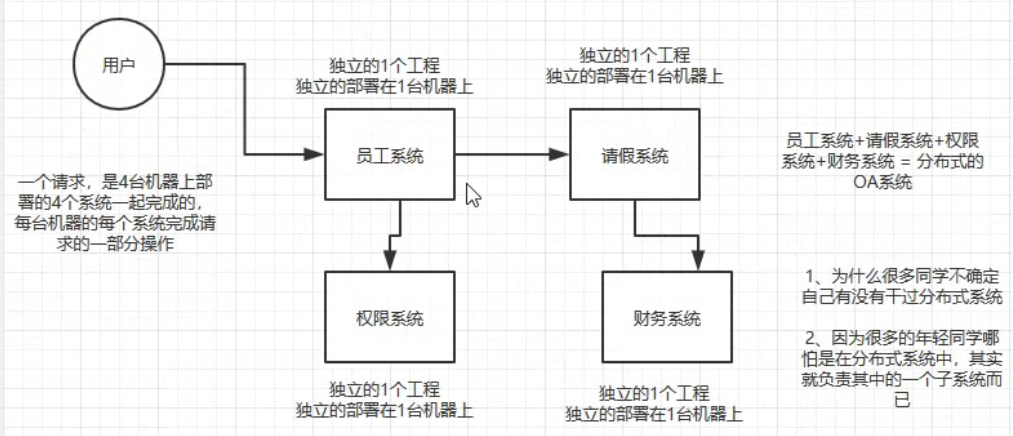
分布式业务系统,是把原来用java开发的一个大块系统,给拆分成多个子系统,多个子系统之间互相调用,形成一个大系统的整体。假设原来你做了一个OA系统,里面包含了权限模块、员工模块、请假模块、财务模块,一个工程,里面包含了一堆模块,模块与模块之间会互相去调用,1台机器部署。现在如果你把他这个系统给拆开,权限系统,员工系统,请假系统,财务系统,4个系统,4个工程,分别在4台机器上部署
一个请求过来,完成这个请求,这个员工系统,调用权限系统,调用请假系统,调用财务系统,4个系统分别完成了一部分的事情,最后4个系统都干完了以后,才认为是这个请求已经完成了。
一个最简单的分布式系统如下图所示:
分布式系统使用较多一款开源RPC框架的是Dubbo,它是一款高性能,轻量级的框架,有三大核心能力:面向接口的远程方法调用、智能容错和负载均衡,以及服务自动注册和发现。
Dubbo可以把每个子系统抽象成一个服务。
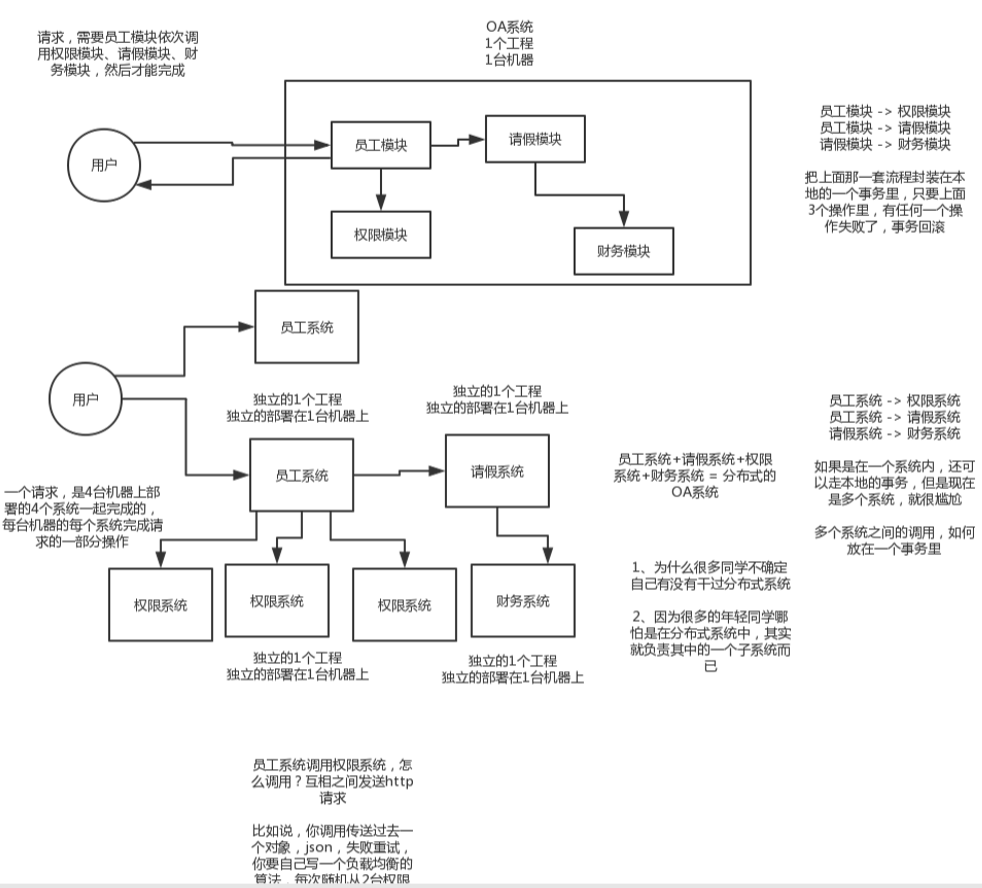
分布式系统,一句话给你解释一下,就是原来20万行代码的系统,现在拆分成20个小系统,每个小系统1万行代码。原本代码之间直接就是基于spring调用,现在拆分开来了,20个小系统部署在不同的机器上,得基于dubbo搞一个rpc调用,接口与接口之间通过网络通信来请求和响应。就这个意思。
CAP 理论
CAP理论,即CAP Theorem。
什么是CAP理论?其实是指,对于一个分布式系统,不能同时满足以下三点:
- 一致性(Consistency)
- 可用性(Avaliability)
- 分区容错性(Partition Tolerance)
Dubbo
为什么要进行系统拆分?
提一嘴微服务,微服务是基于分布式系统的,会把系统拆得更散。
要是不拆分,一个大系统几十万行代码,20个人维护一份代码,简直是悲剧啊。代码经常改着改着就冲突了,各种代码冲突和合并要处理,非常耗费时间;经常我改动了我的代码,你调用了我,导致你的代码也得重新测试,麻烦的要死;然后每次发布都是几十万行代码的系统一起发布,大家得一起提心吊胆准备上线,几十万行代码的上线,可能每次上线都要做很多的检查,很多异常问题的处理,简直是又麻烦又痛苦;而且如果我现在打算把技术升级到最新的spring版本,还不行,因为这可能导致你的代码报错,我不敢随意乱改技术。
假设一个系统是20万行代码,其中小A在里面改了1000行代码,但是此时发布的时候是这个20万行代码的大系统一起发布。一起发布,就意味着20万上代码在线上就可能出现各种变化,20个人,每个人都要紧张地等在电脑面前,上线之后,检查日志,看自己负责的那一块儿有没有什么问题。
小A就检查了自己负责的1万行代码对应的功能,确保ok就闪人了;结果不巧的是,小A上线的时候不小心修改了线上机器的某个配置,导致另外小B和小C负责的2万行代码对应的一些功能,出错了
几十个人负责维护一个几十万行代码的单块应用,每次上线,准备几个礼拜,上线 -> 部署 -> 检查自己负责的功能
维护单块的应用,在从0到1的环节里,是很合适的,因为那个时候,是系统都没上线,没什么技术挑战,大家有条不紊的开发。ssh + mysql + tomcat,可能会部署几台机器吧。
结果不行了,后来系统上线了,业务快速发展,10万用户 -> 100万用户 -> 1000万用户 -> 上亿用户了。
拆分之后,整个世界清爽了,几十万行代码的系统,拆分成20个服务,平均每个服务就1~2万行代码,每个服务部署到单独的机器上。20个工程,20个git代码仓库里,20个程序员,每个人维护自己的那个服务就可以了,是自己独立的代码,跟别人没关系。再也没有代码冲突了,爽。每次就测试我自己的代码就可以了,爽。每次就发布我自己的一个小服务就可以了,爽。技术上想怎么升级就怎么升级,保持接口不变就可以了,爽。
所以简单来说,一句话总结,如果是 那种代码量多达几十万行的中大型项目,团队里有几十个人,那么如果不拆分系统,开发效率极其低下,问题很多。但是拆分系统之后,每个人就负责自己的一小部分就好了,可以随便玩儿随便弄。分布式系统拆分之后,可以大幅度提升复杂系统大型团队的开发效率。
但是同时,也要提醒的一点是,系统拆分成分布式系统之后,大量的分布式系统面临的问题也是接踵而来,所以后面的问题都是在围绕分布式系统带来的复杂技术挑战在说。
如何进行系统拆分?
这个问题说大可以很大,可以扯到领域驱动模型设计上去,说小了也很小。
系统拆分分布式系统,拆成多个服务,拆成微服务的架构,拆很多轮的。上来一个架构师第一轮就给拆好了,第一轮;团队继续扩大,拆好的某个服务,刚开始是1个人维护1万行代码,后来业务系统越来越复杂,这个服务是10万行代码,5个人;第二轮,1个服务 -> 5个服务,每个服务2万行代码,每人负责一个服务。
如果是多人维护一个服务,<=3个人维护这个服务;最理想的情况下,几十个人,1个人负责1个或2~3个服务;某个服务工作量变大了,代码量越来越多,某个同学,负责一个服务,代码量变成了10万行了,他自己不堪重负,他现在一个人拆开,5个服务,1个人顶着,负责5个人,接着招人,2个人,给那个同学带着,3个人负责5个服务,其中2个人每个人负责2个服务,1个人负责1个服务。
一个服务的代码不要太多,1万行左右,最多两三万。
大部分的系统,是要进行多轮拆分的,第一次拆分,可能就是将以前的多个模块该拆分开来了,比如说将电商系统拆分成订单系统、商品系统、采购系统、仓储系统、用户系统,等等吧。
但是后面可能每个系统又变得越来越复杂了,比如说采购系统里面又分成了供应商管理系统、采购单管理系统,订单系统又拆分成了购物车系统、价格系统、订单管理系统。
扯深了实在很深,所以这里先给大家举个例子,你自己感受一下,核心意思就是根据情况,先拆分一轮,后面如果系统更复杂了,可以继续分拆。根据自己负责系统的例子,来考虑一下就好了。
拆分后不用dubbo可以吗?
当然可以了,大不了最次,就是各个系统之间,直接基于spring mvc,就纯http接口互相通信呗,还能咋样。但是这个肯定是有问题的,因为http接口通信维护起来成本很高,你要考虑超时重试、负载均衡等等各种乱七八糟的问题,比如说你的订单系统调用商品系统,商品系统部署了5台机器,你怎么把请求均匀地甩给那5台机器?这不就是负载均衡?你要是都自己搞那是可以的,但是确实很痛苦。
所以dubbo说白了,是一种rpc框架,就是本地就是进行接口调用,但是dubbo会代理这个调用请求,跟远程机器网络通信,给你处理掉负载均衡了、服务实例上下线自动感知了、超时重试了,等等乱七八糟的问题。那你就不用自己做了,用dubbo就可以了。
Dubbo的工作原理?
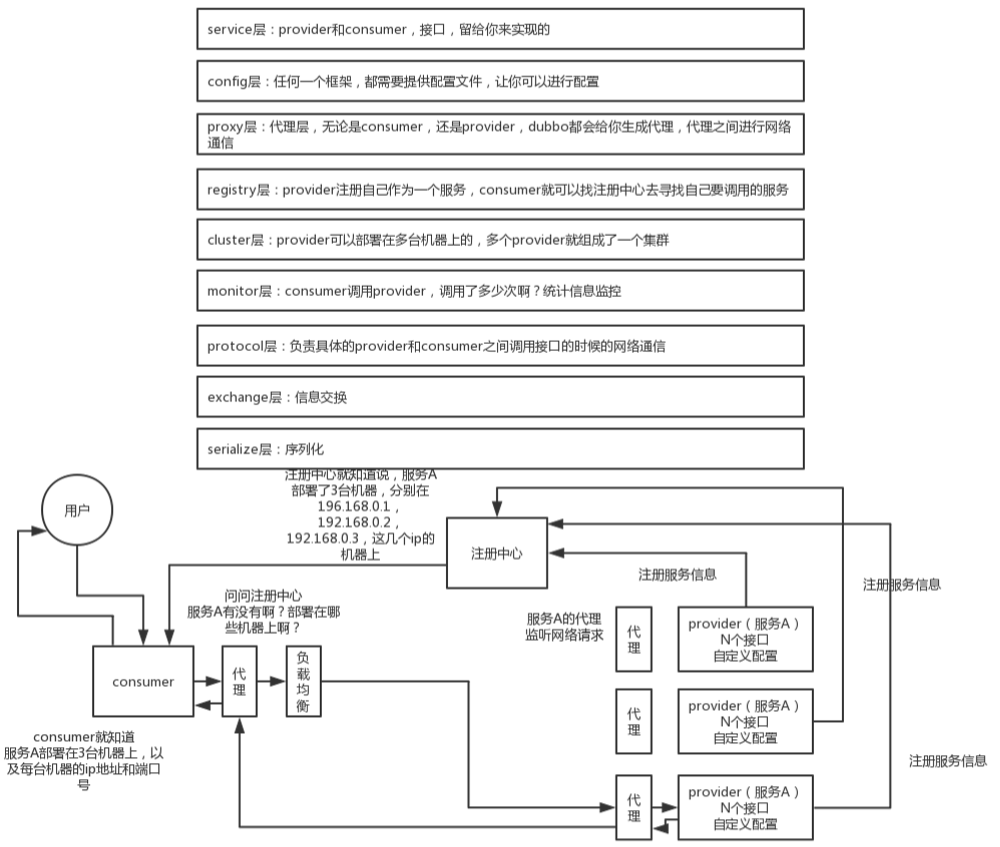
第一层:service层,接口层,给服务提供者和消费者来实现的。用过Dubbo的话,都是写provider、consumer、api,然后可以简单启动。
第二层:config层,配置层,主要是对dubbo进行各种配置的
第三层:proxy层,(服务)代理层,透明生成客户端的stub和服务单的skeleton
第四层:registry层,(服务)注册层,负责服务的注册与发现
第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控
第七层:protocol层,远程调用层,封装rpc调用
第八层:exchange层,信息交换层,封装请求响应模式,同步转异步
第九层:transport层,网络传输层,抽象mina和netty为统一接口
第十层:serialize层,数据序列化层
工作流程:
- 第一步,provider向注册中心去注册
- 第二步,consumer从注册中心订阅服务,注册中心会通知consumer注册好的服务
- 第三步,consumer调用provider。注意,consumer和provider之间通信的时候一定要用到代理的,因为代理可以更方便使用均衡负载等策略来提高系统性能。
- 第四步,consumer和provider都异步的通知监控中心
总的工作原理如下图所示:
注册中心挂了可以继续通信吗?
可以,因为刚开始初始化的时候,消费者会将提供者的地址等信息拉取到本地缓存,所以注册中心挂了不要紧,可以本地缓存信息继续通信。
说一说一次RPC请求的流程?
使用Dubbo的一次通讯请求流程大致如上图。
Dubbo支持哪些通信协议?支持哪些序列化协议?
这个问题也不会问得很深,可能就问一下,什么场景下使用什么协议,然后比较各种序列化协议的优缺点。
dubbo支持不同的通信协议
1)dubbo协议
dubbo://192.168.0.1:20188
默认就是走dubbo协议的,单一长连接,NIO异步通信,基于hessian作为序列化协议。
什么是短连接和长连接?
短连接:每次请求都发送和建立一个连接,建立之后用完了就失效。(下图最后一个为短连接)
长链接:建立一个长期保存的连接,后续再有请求,继续用这个连接。(下图第一个为长连接)
适用的场景就是:传输数据量很小(每次请求在100kb以内),但是并发量很高
如图:
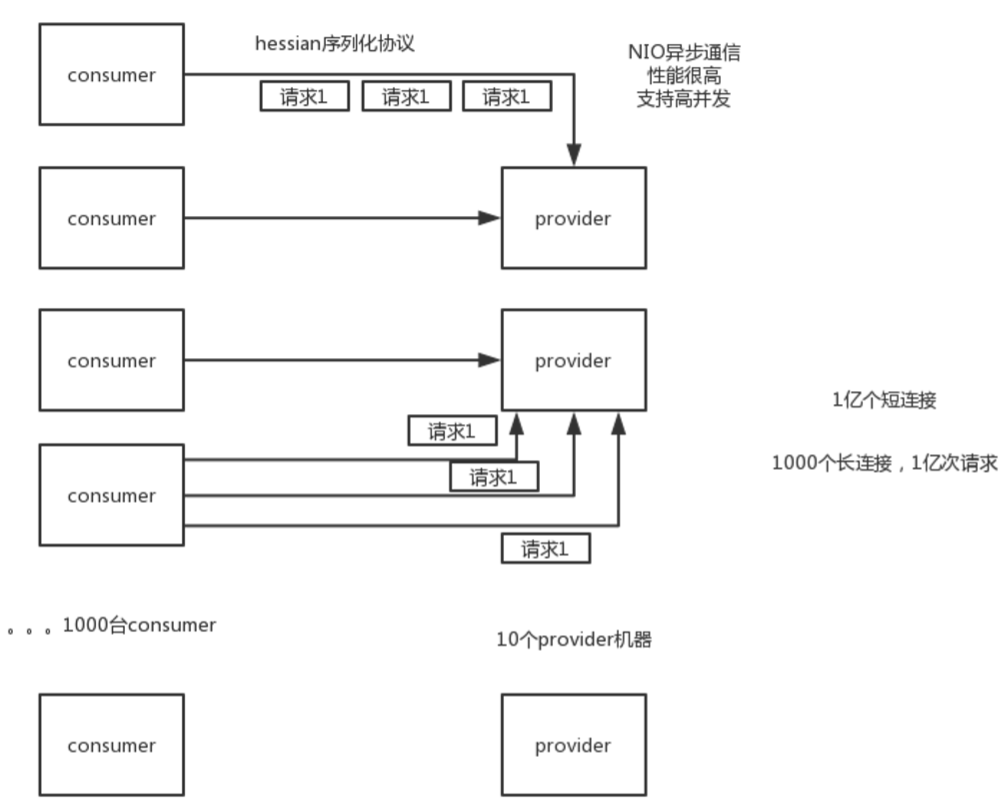
为了要支持高并发场景,一般是服务提供者就几台机器,但是服务消费者有上百台,可能每天调用量达到上亿次!此时用长连接是最合适的,就是跟每个服务消费者维持一个长连接就可以,可能总共就100个连接。然后后面直接基于长连接NIO异步通信,可以支撑高并发请求。
否则如果上亿次请求每次都是短连接的话,服务提供者会扛不住。
而且因为走的是单一长连接,所以传输数据量太大的话,会导致并发能力降低。所以一般建议是传输数据量很小,支撑高并发访问。
hessian使用的最多,剩下四个方法用得比较少。
2)rmi协议
走 java二进制序列化,多个短连接,适合消费者和提供者数量差不多,适用于文件的传输,一般较少用
3)hessian协议
走hessian序列化协议,多个短连接,适用于提供者数量比消费者数量还多,适用于文件的传输,一般较少用
4)http协议
走json序列化
5)webservice
走SOAP文本序列化
dubbo支持的序列化协议
序列化:把数据转换成可以在网络上传输的格式(比如二进制)。
所以dubbo实际基于不同的通信协议,支持hessian、java二进制序列化、json、SOAP文本序列化多种序列化协议。但是hessian是其默认的序列化协议。