世界上最快乐的事,莫过于为理想而奋斗——苏格拉底
LeetCode树、递归相关题目,其解决思路和具体代码。
首先可以使用递归来解决的问题,一般具有如下特点: 1. 该问题可以被分解成若干个重复的子问题; 2. 该问题与它分解出的子问题可以使用相同的算法来解决; 3. 有明确的终止条件。
树这种数据结构的特点和上述三个特点高度一致,一棵树的每个非叶子节点的子节点也都是一棵树,都是树自然可以使用相同的算法来处理,因为没有环所以天然具有终止条件。 另外一方面,树本身是一种非线性的数据结构,循环遍历不易。当然循环遍历也是可以做,树是一种特殊的图,我们完全可以使用图的广度优先遍历算法一层一层的循环遍历整棵树。 综上,我们一般还是选择递归的方式来解决树的问题。
因为树的操作的特性,很多题目可以用递归相关轻易解决,比如树的前中后序遍历。但是非递归的方式同样重要。
除了树,还有分治,回溯和递归相关题目。分治和回溯本质就是递归,递归和回溯是特殊的递归。
有关树的时间复杂度和空间复杂度分析,可以参考下面这张图:
可以发现,因为二叉树每层最多两个元素,按照层级扩散,所以与树相关的结构平均下来的时间复杂度大多是 O(logN) 级别的。
针对递归,一般人们的认识是递归的时间复杂度非常高。但是具体说来,递归算法的时间复杂度如何计算呢?——子问题个数乘以解决一个子问题需要的时间。
Given a binary tree, return the inorder traversal of its nodes’ values.
Example:
1 2 3 4 5 6 7 8 Input: [1 ,null ,2 ,3 ] 1 \ 2 / 3 Output: [1 ,3 ,2 ]
Follow up: Recursive solution is trivial(简单), could you do it iteratively?
解:方法一,递归,时间复杂度较高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution public List<Integer> inorderTraversal (TreeNode root) if (root == null ) return new ArrayList<>(); List<Integer> result = new LinkedList<>(); travelHelper(root, result); return result; } public void travelHelper (TreeNode root, List<Integer> result) if (root == null ) return ; travelHelper(root.left, result); result.add(root.val); travelHelper(root.right, result); } }
方法二,非递归,用一个栈解决。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution public List<Integer> inorderTraversal (TreeNode root) List<Integer> result = new LinkedList<>(); if (root == null ) return result; Stack<TreeNode> stack = new Stack<>(); TreeNode root0 = root; while (root0 != null || !stack.isEmpty()) { while (root0 != null ) { stack.push(root0); root0 = root0.left; } root0 = stack.pop(); result.add(root0.val); root0 = root0.right; } return result; } }
注: 额外定义了一个root0,避免操作之后整棵树找不到了的情况。面试过程中只是为了完成遍历,不定义root0问题也不大。
Given a binary tree, return the preorder traversal of its nodes’ values.
Example:
1 2 3 4 5 6 7 8 Input: [1 ,null ,2 ,3 ] 1 \ 2 / 3 Output: [1 ,2 ,3 ]
Follow up: Recursive solution is trivial, could you do it iteratively?
解:方法一,递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution public List<Integer> preorderTraversal (TreeNode root) List<Integer> result = new LinkedList<>(); if (root == null ) return result; preHelper(root, result); return result; } public void preHelper (TreeNode root, List<Integer> result) if (root == null ) return ; result.add(root.val); preHelper(root.left, result); preHelper(root.right, result); } }
方法二,非递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution public List<Integer> preorderTraversal (TreeNode root) List<Integer> result = new LinkedList<>(); if (root == null ) return result; Stack<TreeNode> stack = new Stack<>(); while (root != null || !stack.isEmpty()) { while (root != null ) { stack.push(root); result.add(root.val); root = root.left; } root = stack.pop(); root = root.right; } return result; } }
注: 额外定义了一个root0,避免操作之后整棵树找不到了的情况。面试过程中只是为了完成遍历,不定义root0问题也不大。
非递归也可以这样写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution public List<Integer> preorderTraversal (TreeNode root) List<Integer> result = new LinkedList<>(); if (root == null ) return result; Stack<TreeNode> stack = new Stack<>(); stack.push(root); while (!stack.isEmpty()) { TreeNode temp = stack.pop(); result.add(temp.val); if (temp.right != null ) stack.push(temp.right); if (temp.left != null ) stack.push(temp.left); } return result; } }
Given a binary tree, return the postorder traversal of its nodes’ values.
Example:
1 2 3 4 5 6 7 8 Input: [1 ,null ,2 ,3 ] 1 \ 2 / 3 Output: [3 ,2 ,1 ]
Follow up: Recursive solution is trivial, could you do it iteratively?
解:方法一,递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution public List<Integer> postorderTraversal (TreeNode root) List<Integer> result = new LinkedList<>(); if (root == null ) return result; postHelper(root, result); return result; } public void postHelper (TreeNode root, List<Integer> result) if (root == null ) return ; postHelper(root.left, result); postHelper(root.right, result); result.add(root.val); } }
方法二,利用通过LinkedList构造的List<>可以用addFirst()方法。因为后序遍历访问节点的顺序刚好和前序相反,所以在同样地方访问节点然后加入到结果集合的头部即可。此外这个方法因为完全模拟前序的相反的结果
需要注意:如果要用LinkedList的addFirst()方法,在定义result的时候左边就要是LinkedList这个实现类型,而不是用List接口,用接口的话不能自动实现addFirst()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution public List<Integer> postorderTraversal (TreeNode root) LinkedList<Integer> result = new LinkedList<>(); if (root == null ) return result; Stack<TreeNode> stack = new Stack<>(); stack.push(root); while (!stack.isEmpty()) { TreeNode temp = stack.pop(); result.addFirst(temp.val); if (temp.left != null ) stack.push(temp.left); if (temp.right != null ) stack.push(temp.right); } return result; } }
但是这个看起来很巧妙(确实也很巧妙,利用后序遍历和前序遍历相反的规律)的方法有Bug,即如果树存在比较复杂的拓扑依赖,这种方法会报出错(但是面试用这个方法应该问题不大)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution public List<Integer> postorderTraversal (TreeNode root) List<Integer> result=new ArrayList<>(); Stack<TreeNode> stack=new Stack<>(); if (root==null ){ return result; } stack.push(root); TreeNode cur=root; TreeNode pre=null ; while (!stack.isEmpty()){ cur=stack.peek(); if (cur.left==null &&cur.right==null ||(pre!=null &&(pre==cur.left||pre==cur.right))){ result.add(cur.val); stack.pop(); pre=cur; }else { if (cur.right!=null ){ stack.push(cur.right); } if (cur.left!=null ){ stack.push(cur.left); } } } return result; } }
Given a binary tree, return the level order traversal of its nodes’ values. (ie, from left to right, level by level).
For example:Given binary tree [3,9,20,null,null,15,7],
return its level order traversal as:
1 2 3 4 5 [ [3 ], [9 ,20 ], [15 ,7 ] ]
解:这道题,在整个硅谷的面试题中,出现次数也是能够排在前三的位置,非常重要。
方法一,递归,DFS。层序遍历用深搜其实有一点”反人类”,但是有助于理解和面试时候的表现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution public List <List <Integer>> levelOrder(TreeNode root) { List <List <Integer>> result = new LinkedList<>(); if (root == null ) return result; levelHelper(result, root ,0 ); return result; } public void levelHelper(List <List <Integer>> result, TreeNode root, int height) { if (root == null ) return ; if (height >= result.size()) { result.add(new LinkedList<Integer>()); } result.get (height).add(root.val); levelHelper(result, root.left, height + 1 ); levelHelper(result, root.right, height + 1 ); } }
方法二,使用队列,使用BFS遍历的模板。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public List <List <Integer >> levelOrder(TreeNode root) { List <List <Integer >> result = new LinkedList<>(); if (root == null ) return result; Queue <TreeNode> queue = new LinkedList<>(); queue .add(root); while (!queue .isEmpty()) { int levelLength = queue .size(); List <Integer > currLevel = new LinkedList<>(); for(int i = 0 ; i < levelLength; i++) { TreeNode currNode = queue .poll(); currLevel.add(currNode.val); if (currNode.left != null ) queue .add(currNode.left); if (currNode.right != null ) queue .add(currNode.right); } result.add(currLevel); } return result; } }
Given a binary tree, return the zigzag level order traversal of its nodes’ values. (ie, from left to right, then right to left for the next level and alternate between).
For example:[3,9,20,null,null,15,7],
return its zigzag level order traversal as:
1 2 3 4 5 [ [3 ], [20 ,9 ], [15 ,7 ] ]
解:上一道102已经解决了层次遍历的问题,可以基于上一题使用队列实现BFS的思想。但是这里需要判断锯齿(或者称为之字型),用变量zigzag记录当前从右向左添加还是从左向右添加元素。zigzag为false,表示从左到右。zigzag为true,表示从右到左。初始的时候为从左到右,即zigzag初始值为false。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution public List<List<Integer>> zigzagLevelOrder(TreeNode root) { List<List<Integer>> result = new ArrayList<>(); if (root == null ) return result; Queue<TreeNode> queue = new LinkedList<>(); queue.add(root); boolean zigzag = false ; while (!queue.isEmpty()) { List<Integer> currLevel = new LinkedList<>(); int currLength = queue.size(); for (int i = 0 ; i < currLength; i++) { TreeNode currNode = queue.poll(); if (zigzag) { currLevel.add(0 , currNode.val); } else currLevel.add(currNode.val); if (currNode.left != null ) queue.add(currNode.left); if (currNode.right != null ) queue.add(currNode.right); } result.add(currLevel); zigzag = !zigzag; } return result; } }
注意: linkedList的add方法,两参数的重构方法中第一个参数为index:
1 2 add (int index, E element ) Inserts the specified element at the specified position in this list.
You need to find the largest value in each row of a binary tree.
Example :
1 2 3 4 5 6 7 8 9 Input : 1 / \ 3 2 / \ \ 5 3 9 Output : [1, 3, 9]
解:因为需要按照层次记录最大值,所以和层次遍历题目有类似之处。
方法一:DFS。深搜大多利用递归,写一个递归函数,直接利用计算机帮你维护的栈即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution { public List<Integer> largestValues(TreeNode root ) { List<Integer> result = new ArrayList<>() ; if (root == null) return result; largestHelper(result , root , 0) ; return result; } public void largestHelper(List<Integer> result , TreeNode root , int height ) { if (root == null) return ; if (height == result.size() ) { result.add(root.val ); } else { result.set(height, Math .val )); } largestHelper(result , root .left , height + 1) ; largestHelper(result , root .right , height + 1) ; } }
方法二:BFS。和树部分102题层次遍历大体结构相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public List <Integer > largestValues(TreeNode root) { List <Integer > result = new LinkedList<>(); if (root == null ) return result; Queue <TreeNode> queue = new LinkedList<>(); queue .offer(root); int max = Integer .MIN_VALUE; while (!queue .isEmpty()) { int levelSize = queue .size(); for(int i = 0 ; i < levelSize; i++) { TreeNode currNode = queue .poll(); max = Math.max (max , currNode.val); if (currNode.left != null ) queue .add(currNode.left); if (currNode.right != null ) queue .add(currNode.right); } result.add(max ); max = Integer .MIN_VALUE; } return result; } }
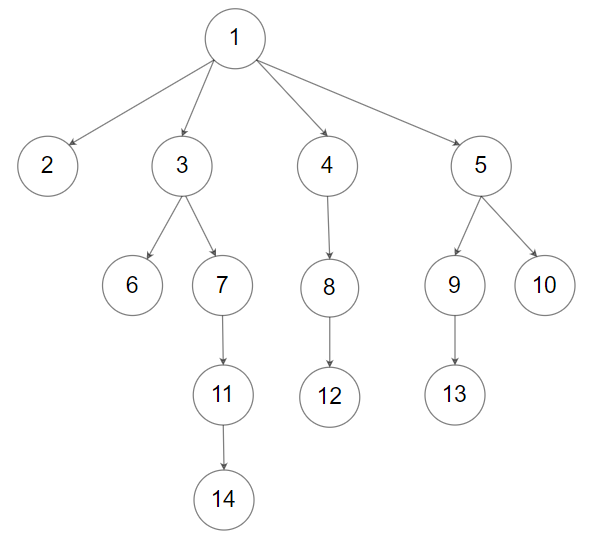
Given an n-ary tree, return the postorder traversal of its nodes’ values.
Nary-Tree input serialization is represented in their level order traversal, each group of children is separated by the null value (See examples).
Follow up:
Recursive solution is trivial, could you do it iteratively?
Example 1:
1 2 Input: root = [1 ,null ,3 ,2 ,4 ,null ,5 ,6 ] Output: [5 ,6 ,3 ,2 ,4 ,1 ]
Example 2:
1 2 Input: root = [1 ,null ,2 ,3 ,4 ,5 ,null ,null ,6 ,7 ,null ,8 ,null ,9 ,10 ,null ,null ,11 ,null ,12 ,null ,13 ,null ,null ,14 ] Output: [2 ,6 ,14 ,11 ,7 ,3 ,12 ,8 ,4 ,13 ,9 ,10 ,5 ,1 ]
Constraints:
The height of the n-ary tree is less than or equal to 1000
The total number of nodes is between [0, 10^4]
解:利用LinkedList的addFirst()遍历树。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 /* // Definition for a Node . class Node { public int val; public List<Node> children; public Node () {} public Node (int _val) { val = _val; } public Node (int _val, List<Node> _children) { val = _val; children = _children; } }; */ class Solution { public List<Integer> postorder(Node root ) { LinkedList<Integer> result = new LinkedList<> (); if(root == null) return result; Stack<Node> stack = new Stack<> (); stack.add(root); while(!stack.empty()) { root = stack.pop(); result.addFirst(root.val); for(Node node : root.children) { stack.add(node ); } } return result; } }
Given an n-ary tree, return the preorder traversal of its nodes’ values.
Nary-Tree input serialization is represented in their level order traversal, each group of children is separated by the null value (See examples).
Follow up:
Example 1:
1 2 Input: root = [1 ,null ,3 ,2 ,4 ,null ,5 ,6 ] Output: [1 ,3 ,5 ,6 ,2 ,4 ]
Example 2:
1 2 Input: root = [1 ,null ,2 ,3 ,4 ,5 ,null ,null ,6 ,7 ,null ,8 ,null ,9 ,10 ,null ,null ,11 ,null ,12 ,null ,13 ,null ,null ,14 ] Output: [1 ,2 ,3 ,6 ,7 ,11 ,14 ,4 ,8 ,12 ,5 ,9 ,13 ,10 ]
Constraints:
The height of the n-ary tree is less than or equal to 1000
The total number of nodes is between [0, 10^4]
解:使用DFS非递归模板。把子树从后往前添加到栈里面,弹出的时候刚好相反,从前往后的顺序弹出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /* // Definition for a Node . class Node { public int val; public List<Node> children; public Node () {} public Node (int _val) { val = _val; } public Node (int _val, List<Node> _children) { val = _val; children = _children; } }; */ class Solution { public List<Integer> preorder(Node root ) { List<Integer> result = new LinkedList<> (); if(root == null) return result; Stack<Node> stack = new Stack<> (); stack.push(root); while(!stack.empty()) { root = stack.pop(); result.add(root.val); for(int i = root.children.size() - 1 ; i >= 0 ; i--) { stack.add(root.children.get(i)); } } return result; } }
Given an n-ary tree, return the level order traversal of its nodes’ values.
Nary-Tree input serialization is represented in their level order traversal, each group of children is separated by the null value (See examples).
Example 1:
1 2 Input: root = [1 ,null ,3 ,2 ,4 ,null ,5 ,6 ] Output: [[1 ],[3 ,2 ,4 ],[5 ,6 ]]
Example 2:
1 2 Input: root = [1 ,null ,2 ,3 ,4 ,5 ,null ,null ,6 ,7 ,null ,8 ,null ,9 ,10 ,null ,null ,11 ,null ,12 ,null ,13 ,null ,null ,14 ] Output: [[1 ],[2 ,3 ,4 ,5 ],[6 ,7 ,8 ,9 ,10 ],[11 ,12 ,13 ],[14 ]]
Constraints:
The height of the n-ary tree is less than or equal to 1000
The total number of nodes is between [0, 10^4]
解:和层序遍历思路相同,只是需要注意N叉树的遍历在内层要多一个循环去遍历所有节点的子节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { public List <List <Integer >> levelOrder(Node root) { List <List <Integer >> result = new LinkedList<>(); if (root == null ) return result; Queue <Node> queue = new LinkedList<>(); queue .add(root); while (!queue .isEmpty()) { int currLength = queue .size(); List <Integer > currLevel = new LinkedList<>(); for(int i = 0 ; i < currLength; i++) { Node currNode = queue .poll(); currLevel.add(currNode.val); for(Node node : currNode.children) { queue .add(node); } } result.add(currLevel); } return result; } }
You are climbing a stair case. It takes n steps to reach to the top.
Each time you can either climb 1 or 2 steps. In how many distinct ways can you climb to the top?
Note: Given n will be a positive integer.
Example 1:
1 2 3 4 5 Input: 2 Output: 2 Explanation: There are two ways to climb to the top. 1 . 1 step + 1 step 2 . 2 steps
Example 2:
1 2 3 4 5 6 Input: 3 Output: 3 Explanation: There are three ways to climb to the top. 1 . 1 step + 1 step + 1 step 2 . 1 step + 2 steps 3 . 2 steps + 1 step
解:爬楼梯很经典,变型也很多。首先结论是,单纯的这道题,通过数学归纳的思路(或者说递归的思路),不难发现其实结果就是前两个元素为1,2的斐波那契数列。(斐波那契数列为509题,因为类似这里就不记录了,链接点击这里 )
方法一:递归,可以画出递归树发现,因为每个层级都会在上一层的数量基础上多出2倍的节点,所以时间复杂度为O(2^n),指数级别,不可以接受。而且实际测试中在N为44的时候会出现超时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution { public int climbStairs(int n) { if (n <= 2 ) return n; return climbHelper(0 ,n); } public int climbHelper(int curr, int target) { if (curr > target) return 0 ; if (curr == target) return 1 ; return climbHelper(curr + 1 , target) + climbHelper(curr + 2 , target); } }
方法二:基于递归,加上备忘录,进行有记忆的递归,可以把之前计算过的结果保存下来,有很好的剪枝效果。因为有记录所有的过程,所以子问题的数量就是f(1),f(2)…,为O(n),而且每个子问题解决的时间为O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public int climbStairs(int n) { int [] memo = new int [n+1 ]; if (n <= 2 ) return n; return climbHelper(0 ,n,memo); } public int climbHelper(int curr, int target, int [] memo) { if (curr > target) return 0 ; if (curr == target) return 1 ; if (memo[curr] > 0 ) return memo[curr]; memo[curr] = climbHelper(curr + 1 , target, memo) + climbHelper(curr + 2 , target, memo); return memo[curr]; } }
方法三:常规动态规划,时间复杂度为O(n),空间复杂度也为O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public int climbStairs(int n) { if (n <= 2 ) return n; int [] dp = new int [n+1 ]; dp[1 ] = 1 ; dp[2 ] = 2 ; for (int i = 3 ; i <= n; i++) { dp[i] = dp[i-1 ] + dp[i-2 ]; } return dp[n]; } }
方法四:基于常规动态规划的优化。在空间复杂度上可以提升到O(1)。实际上在一开始的时间复杂度的基础上都可以进行空间的优化,比如O(n)可以优化到O(1),O(m*n)可以优化到O(n)。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution { public int climbStairs(int n) { if (n <= 2 ) return n; int f1 = 1 , f2 = 2 , f3 = 0 ; for (int i = 3 ; i <= n; i++) { f3 = f1 + f2; f1 = f2; f2 = f3; } return f3; } }
Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses.
For example, given n = 3 , a solution set is:
1 2 3 4 5 6 7 [ "((()))" , "(()())" , "(())()" , "()(())" , "()()()" ]
解:方法一 ,这道题是用递归+剪枝可以轻松解决的典型题目。
可以想象一共有2n个位置来填补括号。然后给上括号的填补条件即可得到符合要求的括号对。
什么条件呢?必须明确,n为几,就一定会有几个左括号和右括号。其中左括号加入的条件,是不超过n。而添加左括号的条件是没有的,也就是随时可以加。而右括号添加有条件,就是左括号个数要大于右括号个数才能添加。
也就是说,左括号的条件时:left < n; 右括号的条件是:left > right && right < n。当然,因为Left<n了,right<left,所以右括号的条件中可以不用写right < n了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution public List<String> generateParenthesis (int n) List<String> result = new ArrayList<>(); _generate( 0 , 0 , n, "" ,result); return result; } public void _generate (int left, int right, int n, String s, List<String> result) if (left == n && right == n) { result.add(s); return ; } if (left < n) _generate(left+1 , right, n, s + "(" , result); if (left > right) _generate(left, right + 1 , n, s + ")" , result); } }
时间复杂度上,因为每个子问题处理的时间为O(1),一共的子问题数量是O(2n),也就是O(n)
方法二: 动态规划。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution public List<String> generateParenthesis (int n) if (n <= 0 ) return new ArrayList<String>(); List<List<String>> dp = new LinkedList<>(); dp.add(Collections.singletonList("" )); for (int i = 1 ; i <= n; i++) { List<String> curr = new LinkedList<>(); for (int j = 0 ; j < i; j++) { for (String first : dp.get(j)) { for (String second : dp.get(i-j-1 )) { curr.add("(" + first + ")" + second); } } } dp.add(curr); } return dp.get(dp.size()-1 ); } }
Invert a binary tree.
Example:
Input:
1 2 3 4 5 4 / \ 2 7 / \ / \ 1 3 6 9
Output:
1 2 3 4 5 4 / \ 7 2 / \ / \ 9 6 3 1
Trivia:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so f*** off.
解:方法一,DFS,用递归实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 /** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left ; * TreeNode right ; * TreeNode(int x) { val = x; } * } */ class Solution { public TreeNode invertTree(TreeNode root) { if (root == null ) return null ; TreeNode left = root.left , right = root.right ; root.left = invertTree(right ); root.right = invertTree(left ); return root; } }
方法二,非递归,BFS,用队列实现。本质上是针对层次进行翻转,故可以在层次遍历的基础上把每一层的两个子树交换即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 /** * Definition for a binary tree node . * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public TreeNode invertTree(TreeNode root) { if(root == null) return null; Queue<TreeNode> queue = new LinkedList<> (); queue.add(root); while(!queue.isEmpty()) { TreeNode node = queue .poll(); TreeNode tempNode = node .left ; node .left = node .right ; node .right = tempNode; if(node .left != null) queue.add(node .left ); if(node .right != null) queue.add(node .right ); } return root; } }
Given a binary tree, determine if it is a valid binary search tree (BST).
Assume a BST is defined as follows:
The left subtree of a node contains only nodes with keys less than the node’s key.
The right subtree of a node contains only nodes with keys greater than the node’s key.
Both the left and right subtrees must also be binary search trees.
Example 1:
1 2 3 4 5 6 2 / \ 1 3 Input: [2 ,1 ,3 ] Output: true
Example 2:
1 2 3 4 5 6 7 8 9 5 / \ 1 4 / \ 3 6 Input : [5 ,1 ,4 ,null ,null ,3 ,6 ]Output: false Explanation: The root node's value is 5 but its right child' s value is 4.
解:验证是否为二叉搜索树 是一道经常考的题目,root0.val为当前遍历的节点,inorderVal为上一个节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution public boolean isValidBST (TreeNode root) if (root == null ) return true ; double inorderVal = -Double.MAX_VALUE; TreeNode root0 = root; Stack<TreeNode> stack = new Stack<>(); while (!stack.isEmpty() || root0 != null ) { while (root0 != null ) { stack.push(root0); root0 = root0.left; } root0 = stack.pop(); if (root0.val <= inorderVal) return false ; inorderVal = root0.val; root0 = root0.right; } return true ; } }
注意 ,在LeetCode平台上,输入的root为空,最终返回的也是true。
时间复杂度 : O(N)。每个结点访问一次。
空间复杂度 : O(N)。我们跟进了整棵树。
验证二叉搜索树(2019快手秋招工程A卷) 给定一棵满二叉树,判定该树是否为二叉搜索树,是的话打印True,不是的话打印False
说明:
输入描述:
从根节点开始,逐层输入每个节点的值,空树或空节点输入为None
比如:10,5,15,3,7,13,18
输出描述:
是二叉搜索树的话打印True,不是的话打印False
示例1
输入:10,5,15,3,7,13,18
输出:True
解:这道题虽然目的和LeetCode98相同,但是不能直接用中序遍历,需要自己构建一颗树,或者直接用二叉树层次结构父节点和子节点的index关系来做。(所有企业笔试都需要自己构建输入输出,这点需要比较注意。但是其实也不难,写几次就知道了。)
这道题问题在于处理输入,如果只是单纯判断某一棵树是不是为二叉搜素树,判断其中序遍历结果是否为递增的即可。但是这里输入不是一棵树,而且输入可能会有空(用None)表示。
但是好消息是,题目已经明确说给定的会是一颗满二叉树或者干脆为None值,方便我们处理。
所以这里需要利用树的父节点和子节点的下标关系来进行比较(和一开始我们讨论的堆建树过程差不多)。重点是父节点下标和子节点下标之间的关系:第i个节点,它的左孩子为 tree[2 * i]、右孩子为tree[2*i+1]
也可以自己建立树,通过输入的结果进行层序遍历,依次赋值
Given a binary tree, flatten it to a linked list in-place.
For example, given the following tree:
1 2 3 4 5 1 / \ 2 5 / \ \ 3 4 6
The flattened tree should look like:
1 2 3 4 5 6 7 8 9 10 11 1 \ 2 \ 3 \ 4 \ 5 \ 6
解:本题详细题解参考这篇文章
首先需要注意,这棵树是二叉树,不是二叉搜索树 ,所以不要想用中序遍历得到递增的遍历结果。
结合题目意思,可以看到,把二叉树展开成链表,实际上就是把二叉树变成原先先序遍历的结果的链表。但是因为要in-place,所以原则上只能在原先二叉树上进行操作。
方法一:不考虑原地(in-place)的操作,先序遍历整棵树,把它们放到一个数组里,然后利用TreeNode依次构建新的树,时间复杂度和空间复杂度都是O(n)。当然,因为不遵从in-place,这种方法可能不行。
方法二:同样用先序遍历,具体流程是:
将左子树插入到右子树的地方
将原来的右子树接到左子树的最右边节点
考虑新的右子树的根节点,一直重复上边的过程,直到新的右子树为null
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution public void flatten(TreeNode root) { while (root != null) { if (root.left == null) { root = root.right ; } else { TreeNode pre = root.left ; while (pre.right != null) { pre = pre.right ; } pre.right = root.right ; root.right = root.left ; root.left = null; root = root.right ; } } } }
方法三:递归
虽然要求In-place,但是意思不是时间复杂度必须O(1),而是直接在原来节点上改变指向,对空间复杂度没有要求,所以可以用递归解的。
递归解法实际上是通过二叉树的右指针 ,组成一个链表。
按照题意最后链表的顺序是先序遍历的结果,那么我们可以就按照先序遍历,然后每遍历一个节点,就让上一个遍历的节点的右指针更新为当前节点。
但是这样的话有一个很绝望的问题,就是,如果直接这么做,上一个节点的右孩子就会丢失。比如题目给的样例,先序遍历顺序是1,2,3,4,5,6,那么如果遍历到2,把1的右指针指向2,那么1本身的右孩子(也就是5)会丢失,即没有指针指向5了。
解决方法就是后序遍历,然后每次让当前节点右指针指向上一个节点。比如访问5,让5的右指针指向6.遍历4,让4的右指针指向5.这样一来就没有指针丢失的问题了,因为更新当前右指针的时候,当前节点的右孩子已经访问过了。
可以用一个全局变量pre,每次更新当前节点的右指针为pre,左指针为null。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution private TreeNode pre = null ; public void flatten(TreeNode root) { if (root == null ) return ; flatten(root.right); flatten(root.left); root.right = pre; root.left = null ; pre = root; } }
这段代码虽然简洁,但是还是比较难想的。一个记忆技巧可以是,首先找到所有结点的最右孩子节点,然后每次都先访问右孩子,让pre指向root.right,然后清空左孩子节点,最后把pre往前移动即可。
Given a binary tree, find its maximum depth.
The maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
Note: A leaf is a node with no children.
Example: [3,9,20,null,null,15,7],
return its depth = 3.
解:方法一,递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution public int maxDepth(TreeNode root) { if (root == null ) return 0 ; int leftDepthMax = maxDepth(root.left); int rightDepthMax = maxDepth(root.right); return Math.max(leftDepthMax, rightDepthMax) + 1 ; } }
写得漂亮一些,可以用一行解决:
1 2 3 4 5 class Solution { public int maxDepth(TreeNode root ) { return root == null ? 0 : Math .Depth(root .left ) ,maxDepth(root .right ) ) + 1 ; } }
复杂度分析:
时间复杂度:我们每个结点只访问一次,因此时间复杂度为 O(N),
空间复杂度:在最糟糕的情况下,树是完全不平衡的,例如每个结点只剩下左子结点,递归将会被调用 N 次(树的高度),因此保持调用栈的存储将是 O(N)。但在最好的情况下(树是完全平衡的),树的高度将是 log(N)。因此,在这种情况下的空间复杂度将是 O(log(N))。
方法二,迭代,用BFS层次遍历的方法,遍历完之后层数就是最大深度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int maxDepth (TreeNode root) if (root == null) return 0 ; Queue<TreeNode> queue = new LinkedList<>(); queue .add(root); int maxDepth = 0 ; while (!queue .isEmpty()) { maxDepth ++; int currLength = queue .size (); for (int i = 0 ; i < currLength; i++) { TreeNode node = queue .poll(); if (node.left != null) queue .add(node.left); if (node.right != null) queue .add(node.right); } } return maxDepth; } }
注: 综合下来这道题用递归解法时间和空间复杂度都更优,因为平衡二叉树的情况下栈的调用次数只有log(n)。
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node.
Note: A leaf is a node with no children.
Example: [3,9,20,null,null,15,7],
return its minimum depth = 2.
解:递归是最直接的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution public int minDepth(TreeNode root) { if (root == null) return 0 ; int left = minDepth(root.left ); int right = minDepth(root.right ); return (left == 0 || right == 0 ) ? left + right + 1 : Math .min (left ,right ) + 1 ; } }
时间复杂度:我们访问每个节点一次,时间复杂度为 O(N) ,其中 N 是节点个数。
空间复杂度:最坏情况下,整棵树是非平衡的,例如每个节点都只有一个孩子,递归会调用 N (树的高度)次,因此栈的空间开销是 O(N) 。但在最好情况下,树是完全平衡的,高度只有 log(N),因此在这种情况下空间复杂度只有 O(log(N)) 。
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例:
1 2 3 4 5 6 7 8 9 你可以将以下二叉树: 1 / \ 2 3 / \ 4 5 序列化为 "[1,2,3,null,null,4,5]"
提示 : 这与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
说明: 不要使用类的成员 / 全局 / 静态变量来存储状态,你的序列化和反序列化算法应该是无状态的。
解:可以看出来,序列化和反序列化在实际中应用非常广泛也非常的重要。如果没有序列化,数据结构无法存储到文件和内存里面,通过网络的传输效率也会很低。
因为需要完成序列化和反序列化两个函数,所以需要两个思路:序列化的思想是利用dfs的先序遍历得到一个完整的序列,遇到了null直接存储null即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public class Codec { public String serialize (TreeNode root) return serializeHelper(root, "" ); } private String serializeHelper (TreeNode root, String str) if (root == null) { str += "null," ; return str; } str += root.val + "," ; str = serializeHelper(root.left, str); str = serializeHelper(root.right, str); return str; } public TreeNode deserialize (String data) String [] data_ = data.split("," ); List<String > list = new LinkedList<>(Arrays.asList(data_)); return desHelper(list ); } private TreeNode desHelper (List<String > list ) if (list .get (0 ).equals("null" )) { list .remove (0 ); return null; } int val = Integer.valueOf(list .get (0 )); TreeNode root = new TreeNode(val); list .remove (0 ); root.left = desHelper(list ); root.right = desHelper(list ); return root; } }
时间复杂度:在序列化和反序列化函数中,我们只访问每个节点一次,因此时间复杂度为 O(n),其中 n 是节点数,即树的大小。
空间复杂度:在序列化和反序列化函数中,我们将整棵树保留在开头或结尾,因此,空间复杂性为 O(n)。
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself ).”
Given the following binary tree: root = [3,5,1,6,2,0,8,null,null,7,4]
Example 1:
1 2 3 Input: root = [3 ,5 ,1 ,6 ,2 ,0 ,8 ,null ,null ,7 ,4 ], p = 5 , q = 1 Output: 3 Explanation: The LCA of nodes 5 and 1 is 3.
Example 2:
1 2 3 Input: root = [3 ,5 ,1 ,6 ,2 ,0 ,8 ,null ,null ,7 ,4 ], p = 5 , q = 4 Output: 5 Explanation: The LCA of nodes 5 and 4 is 5 , since a node can be a descendant of itself according to the LCA definition.
Note:
All of the nodes’ values will be unique.
p and q are different and both values will exist in the binary tree.
解:递归代码简单而且时间空间复杂度和迭代相同。
递归的base case:递归过程中如果root 是null,则返回null;如果递归到了子过程,比如(5, 5, 8),则忽略其他内容返回传入的头结点(5),同理如果到了(5, 8, 5),同样忽略其他节点返回5。
1 if (root == null || root == p || root == q) return root ;
之后进行递归调用,每次drill down 根节点的左孩子和右孩子。递归过程一般有四种:
递归的时候总会传入整个结构的根节点。拿题目给的树为例,如果递归到了(2, 6, 0),即p和q都不为根节点的左子树和右子树节点,则返回null。(但是编写代码过程中貌似到不了这种情况,在递归过程中已经过滤掉了)。
传入的p和q中没有根节点右孩子节点,比如(3, 5, 4),此时返回左子树靠上节点:5
传入的p和q中没有根节点左孩子节点,比如(3, 1, 0), 此时返回右子树靠上节点:1
传入的p和q分别为根节点的左孩子节点和右孩子节点,比如(3, 6, 8),返回根节点:3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if (root == null || root == p || root == q) return root; TreeNode left = lowestCommonAncestor(root.left, p, q); TreeNode right = lowestCommonAncestor(root.right, p, q); if (left != null && right != null ) return root; return left != null ? left : right; } }
时间复杂度:O(N),N 是二叉树中的节点数,最坏情况下,我们需要访问二叉树的所有节点。
空间复杂度:O(N),这是因为递归堆栈使用的最大空间位 N,斜二叉树的高度可以是 N。
Given preorder and inorder traversal of a tree, construct the binary tree.
Note:
For example, given
1 2 preorder = [3 ,9 ,20 ,15 ,7 ] inorder = [9 ,3 ,15 ,20 ,7 ]
Return the following binary tree:
解:这个题解过程在大学期间的数据结构课程应当有掌握。先序遍历的顺序总是根节点的顺序。我们可以根据先序遍历过程中遍历过的点逐渐判断哪些是根节点,然后中序遍历数组中在根节点左边的就是左子树,在右边的就是这个根节点的子树。
首先,preorder中的第一个元素一定是树的根,这个根又将inorder序列分成了左右两棵子树。现在我们只需要将先序遍历的数组中删除根元素,然后重复这个过程处理左右两棵子树。
解法一,直接使用上述原理,利用递归进行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { public TreeNode buildTree(int [] preorder, int [] inorder) { return helper(0 , 0 , inorder.length - 1 , preorder, inorder); } public TreeNode helper(int preStart, int inStart, int inEnd, int [] preorder, int [] inorder) { if (preStart > preorder.length - 1 || inStart > inEnd) { return null ; } TreeNode root = new TreeNode(preorder[preStart]); int inIndex = 0 ; for (int i = inStart; i <= inEnd; i++) { if (inorder[i] == root.val) { inIndex = i; } } root.left = helper(preStart + 1 , inStart, inIndex - 1 , preorder, inorder); root.right = helper(preStart + inIndex - inStart + 1 , inIndex + 1 , inEnd, preorder, inorder); return root; } }
解法二,因为在递归过程中每次都要遍历中序遍历的数组去寻找,所以可以利用HashMap,把inorder[],即中序遍历数组的每一个元素的值和下标存起来,这样可以直接用当前先序的值获取中序数组的下标位置了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public TreeNode buildTree(int [] preorder , int [] inorder ) { Map<Integer, Integer> map = new HashMap<>() ; for(int i = 0 ; i < inorder.length; i++) { map.put(inorder[i ] ,i); } TreeNode root = Helper(preorder , 0, preorder .length - 1, inorder , 0, inorder .length - 1, map ) ; return root; } public TreeNode Helper(int [] preorder , int preStart , int preEnd , int [] inorder , int inStart , int inEnd , Map<Integer, Integer> map ) { if (preStart > preEnd || inStart > inEnd) return null; TreeNode root = new TreeNode(preorder [preStart ]) ; int inRoot = map.get(root.val ); int numsLeft = inRoot - inStart; root.left = Helper(preorder , preStart + 1, preStart + numsLeft , inorder , inStart , inRoot - 1,map ) ; root.right = Helper(preorder , preStart + numsLeft + 1, preEnd , inorder , inRoot + 1, inEnd ,map ) ; return root; } }
利用HashMap可以大大提高效率,因为哈希表平均情况下查找效率为O(1)
时间复杂度:O(n),可用主定理计算得到
空间复杂度:O(n),存储整棵树的开销
剑指offer面试题54.二叉搜索树的第k大节点 给定一棵二叉搜索树,请找出其中第k大的节点。
示例1:
1 2 3 4 5 6 7 输入: root = [3 ,1 ,4 ,null ,2 ], k = 1 3 / \ 1 4 \ 2 输出: 4
示例2:
1 2 3 4 5 6 7 8 9 输入: root = [5 ,3 ,6 ,2 ,4 ,null ,null ,1 ], k = 3 5 / \ 3 6 / \ 2 4 / 1 输出: 4
限制:
1 ≤ k ≤ 二叉搜索树元素个数
解:二叉搜索树的中序遍历能够保证结果是从小到大的。现在如果要第k大,即要找从大到小的。我们可以改变访问树的节点的顺序:本来中序遍历是左孩子、根节点、右孩子。我们可以把左孩子和右孩子的访问顺序改变一下,这样结果就是从大到小的了,用flag做记录,到了k之后记录当前值即可。
中序遍历代码可以用94题的中序遍历代码模板。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution public int kthLargest(TreeNode root, int k) { int flag = 0 , result = 0 ; Stack<TreeNode> stack = new Stack<>(); while (root != null || !stack.isEmpty()) { while (root != null ) { stack.push(root); root = root.left; } root = stack.pop(); flag++; if (flag == k) { result = root.val; return result; } root = root.right; } return result; } }
实现 pow(x, n) ,即计算 x 的 n 次幂函数。
Example 1:
1 2 Input: 2.00000 , 10 Output: 1024.00000
Example 2:
1 2 Input: 2.10000 , 3 Output: 9.26100
Example 3:
1 2 3 Input: 2.00000 , -2 Output: 0.25000 Explanation: 2 ^(-2 ) = 1 /(2 ^2 ) = 1 /4 = 0.25
Note:
-100.0 < x < 100.0
n is a 32 bit signed integer, within the range [−2^31, 2^(31 − 1)]
解:面试中碰到,首先需要和面试官确定一些事情(经常需要做的):是否允许调用库函数?更重要的是,x和n的取值范围?x和n是否可以取0,正负值之类的。
其实我们在小学初中就学过某个数的几次方,就是把它乘几个自己,但是在高等数学中不是这么做的,在这里就进行一下计算。
方法一:暴力,求Pow就直接乘出来,时间复杂度为O(n),提一嘴就行。
方法二,利用回溯和二分查找。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public double myPow(double x, int n) { if (n == Integer.MIN_VALUE && x > 1 ) return 0 ; if (n == 0 ) return 1 ; if (n < 0 ) { n = -n; x = 1 / x; } return (n % 2 == 0 ) ? myPow(x * x, n / 2 ) : x * myPow(x * x, n / 2 ); } }
下面八道题为利用回溯解决的几个经典问题:求子集、排列问题、组合问题。此外还加上了分割回文串问题。虽然不是数字的list了,但是也是对List<List>的操作以及回溯法的使用。
参考LeetCode国际站回答: 点击这里 这些问题可以利用相同的一套解题模板,具体思路过程是:选择->拓展->剔除。
还有一点,这几道题最后返回的结果都是List<List<>>()类型的,即list里面装了list,如果不熟练,可能新手写起来都会存在困惑和错误。需要注意因为List不是基本数据类型,每次添加到result中时都需要new出来新的对象才可以,这也是对操作java中的list集合对象的熟练程度的考察。
此外,在过程中每次都是使用result.add(new ArrayList<>(curList)),是因为curList在回溯过程中每次都会被改变,我们需要记录当前curList的结果而不能让后面的curList的内容改变当前curList的结果。
Given two integers n and k, return all possible combinations of k numbers out of 1 … n .
Example:
1 2 3 4 5 6 7 8 9 10 Input: n = 4 , k = 2 Output: [ [2 ,4 ], [3 ,4 ], [2 ,3 ], [1 ,2 ], [1 ,3 ], [1 ,4 ], ]
解:这道题是很典型的用分治,回溯。这个题目递归最重要的两件事:递归终止条件和递归里面的for循环做的事情。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public List<List<Integer>> combine(int n, int k) { List<List<Integer>> results = new ArrayList<>() ; if (n <= 0 || k <= 0 ) return results; combineHelper(n , k , 1, results , new ArrayList<Integer>() ); return results; } public void combineHelper(int n , int k , int st_num , List<List<Integer>> results , List<Integer> curSeq ) { if (k == 0 ) results.add(new ArrayList<Integer> (curSeq)); else { for(int i = st_num; i <= n; i++) { curSeq.add(i); combineHelper(n , k -1, i + 1, results , curSeq ) ; curSeq.remove(curSeq.size() -1 ); } } } }
Given a set of candidate numbers (candidates) (without duplicates ) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target.
The same repeated number may be chosen from candidates unlimited number of times.
Note:
All numbers (including target) will be positive integers.
The solution set must not contain duplicate combinations.
Example 1:
1 2 3 4 5 6 Input: candidates = [2 ,3 ,6 ,7 ], target = 7 , A solution set is : [ [7 ], [2 ,2 ,3 ] ]
Example 2:
1 2 3 4 5 6 7 Input: candidates = [2 ,3 ,5 ], target = 8 , A solution set is : [ [2 ,2 ,2 ,2 ], [2 ,3 ,3 ], [3 ,5 ] ]
解:需要注意的是只要和为target,candidates里面的元素每一个都可以被无限次选择。
看起来和上一道,77组合问题,有相似之处,但是解决起来复杂比较多,因为既需要考虑和是否为target,同时candidates里面的元素可以无限次数选择,加大了难度。
但是可以套用解决这几道回溯(写递归)问题的一系列问题的模板。
首先排序,用于剪枝。不排序也可以通过,但是先排序能够提升最后的空间和时间复杂度。
这样只要当前值比剩余的target大了,后面都是递增的,则可以break跳出了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public List<List<Integer>> combinationSum(int [] candidates , int target ) { List<List<Integer>> result = new ArrayList<>() ; if (target == 0 || candidates == null || candidates.length == 0 ) return result; Arrays . Helper(result , candidates , target , new ArrayList<>() , 0 ); return result; } public void Helper(List<List<Integer>> result , int [] candidates , int remain , List<Integer> curList , int start ) { if (remain < 0 ) return ; else if (remain == 0 ) result.add(new ArrayList<>(curList)); else { for(int i = start; i < candidates.length; i++) { curList.add(candidates[i ] ); Helper(result , candidates , remain - candidates [i ], curList , i ) ; curList.remove(curList.size() - 1 ); } } } }
上述的for循环中的三行内容为回溯常用的写法,在curList中,先curList.add()加进去,再递归处理得到结果,再从curList中移除掉。
回溯的过程是怎样的呢?举个例子,如果candidates为[1,2,3,4,5], target为7,一开始加入的结果是[1,2,3],然后为[1,2,3,4]的时候,此时remain < 0,所以return 回到curList为[1,2,3]的时候,此时需要执行curList.remove(curList.size() - 1),即curList又变成[1,2],然后再放入4, curList变成[1,2,4],再往后执行,以此类推。
时间复杂度:组合问题,指数级的,O(2^n)。因为最终是从所有candidates的组合中选择出符合要求的,所有的情况是2^n的,所以整体时间复杂度就是O(2^n)。
Given a collection of candidate numbers (candidates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target.
Each number in candidates may only be used once in the combination.
Note:
All numbers (including target) will be positive integers.
The solution set must not contain duplicate combinations.
Example 1:
1 2 3 4 5 6 7 8 Input: candidates = [10 ,1 ,2 ,7 ,6 ,1 ,5 ], target = 8 , A solution set is : [ [1 , 7 ], [1 , 2 , 5 ], [2 , 6 ], [1 , 1 , 6 ] ]
Example 2:
1 2 3 4 5 6 Input: candidates = [2 ,5 ,2 ,1 ,2 ], target = 5 , A solution set is : [ [1 ,2 ,2 ], [5 ] ]
解:39题的变题。和39相比的区别是,给的candidates数组可能包含重复元素、结果的list中不能有重复元素。
在去重思路上有一点变化。首先结果中不能重复使用candidates中的元素,所以在递归中start元素要变成i+1。此外,因为candidates中可以有重复元素,所以也要避免重复使用相同元素,在for循环中加一个判断。其他相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public List<List<Integer>> combinationSum2(int [] candidates , int target ) { List<List<Integer>> result = new ArrayList<>() ; if (target == 0 || candidates == null || candidates.length == 0 ) return result; Arrays . Helper(result , candidates , target , new ArrayList<>() , 0 ); return result; } public void Helper(List<List<Integer>> result , int [] candidates , int remain , List<Integer> curList , int start ) { if (remain < 0 ) return ; if (remain == 0 ) result.add(new ArrayList<>(curList)); else { for(int i = start; i < candidates.length; i++) { if (i > start && candidates[i ] == candidates[i -1 ] ) continue; curList.add(candidates[i ] ); Helper(result , candidates , remain - candidates [i ], curList , i +1) ; curList.remove(curList.size() - 1 ); } } } }
时间复杂度:指数级的,O(2^n),推理方法和39题相同。
Given a collection of distinct integers, return all possible permutations.
Example:
1 2 3 4 5 6 7 8 9 10 Input: [1 ,2 ,3 ] Output: [ [1 ,2 ,3 ], [1 ,3 ,2 ], [2 ,1 ,3 ], [2 ,3 ,1 ], [3 ,1 ,2 ], [3 ,2 ,1 ] ]
解:这是一个典型的用递归解决的问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution { public List<List<Integer >> permute(int [] nums) { List<List<Integer >> result = new ArrayList<>(); if (nums == null || nums.length == 0 ) return result; permuteHelper(result, new ArrayList<Integer >(), nums); return result; } public void permuteHelper(List<List<Integer >> result, List<Integer > curList, int [] nums) { if (curList.size() == nums.length) { result.add (new ArrayList<>(curList)); } else { for (int i = 0 ; i < nums.length; i++) { if (curList.contains(nums[i])) continue ; // element already exists , skip curList.add (nums[i]); permuteHelper(result,curList,nums); curList.remove(curList.size() - 1 ); } } } }
可以想象,每一位都是从nums[0]开始,递归完(nums[0],nums[1],nums[2])之后,从list中remove掉nums[2],发现会掉入if(curList.contains(nums[i]))的条件,所以会紧接着remove掉nums[1]。再之后会尝试往curList中加入nums[2],因为此时nums[0]和nums[2]都已经在list中有了,所以会在continue之后加入nums[1],再continue一次,然后以nums[0]作为第一个元素的list的答案就结束了,后面第一个元素变成nums[1],再进行递归。
之前有一个不清楚的困扰,就是为什么result.add(curList)会返回空的list,必须result.add(new ArrayList<>(curList))才可以返回有值的结果。后来发现应该是单纯的add能加入的只能是基本数据类型,而要加入的curList是引用类型,需要new 以curList为内容的list才能加入。也可以理解为,在递归过程中curList总会变化,所以每次新加的是为了记录当前curList的内容的值,需要new才可以。
这道题是非常经典的一道题,这种递归的写法对于初学者可能会比较难思考的,建议多重复几遍,参考我上面这两段文字,更利于理解。
Given a collection of numbers that might contain duplicates, return all possible unique permutations.
Example:
1 2 3 4 5 6 7 Input: [1 ,1 ,2 ] Output: [ [1 ,1 ,2 ], [1 ,2 ,1 ], [2 ,1 ,1 ] ]
解:47是46的变题。输入的nums可能存在重复的元素,实际上,重复的元素也是最重要的考量因素。
有了重复元素之后,整个逻辑和46就已经完全不同了。如果仍然使用46的contains去在循环过程中剔除掉,那么根本凑不足排列的元素数量。所以在往curList里面添加元素的过程中的逻辑需要改变。
在遍历每个元素的过程中,我们也要考虑去重,同一个元素不能被多次使用。而对于这道题,相等的元素也不能被多次使用。
具体到实现上,因为nums[]没说排好序了,所以为了方便根据前后元素进行判重,所以相比46题需要先排序。此外,因为nums[]中存在重复元素,需要判断当前元素是否使用的情况,所以要定义一个boolean数组:used。
为什么用一个boolean数组可以对去重复情况有效? 重复的元素中,前面的不取,后面的取 。其他情况比如前面和后面都取、前面取后面不取、前面后面都不取,这些都不会是重复的情况。读者可以自行举例推演验证。
为了方便记忆,实际上,used数组成为了循环内部判断的条件,不再需要使用curList.contains()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public List<List<Integer>> permuteUnique(int [] nums ) { List<List<Integer>> result = new ArrayList<>() ; if (nums.length == 0 || nums == null) return result; Arrays . permuteUniqueHelper(result , nums , new ArrayList<>() , new boolean[nums .length ] ); return result; } public void permuteUniqueHelper(List<List<Integer>> result , int [] nums , List<Integer> curList , boolean [] used ) { if (curList.size() == nums.length) { result.add(new ArrayList<>(curList)); } else { for(int i = 0 ; i < nums.length; i++) { if (used[i ] || i > 0 && nums[i ] == nums[i -1 ] && !used[i -1 ] ) continue; used[i ] = true ; curList.add(nums[i ] ); permuteUniqueHelper(result , nums , curList , used ) ; used[i ] = false ; curList.remove(curList.size() - 1 ); } } } }
Given a set of distinct integers, nums , return all possible subsets (the power set).
Note : The solution set must not contain duplicate subsets.
Example:
1 2 3 4 5 6 7 8 9 10 11 12 Input: nums = [1 ,2 ,3 ] Output: [ [3 ], [1 ], [2 ], [1 ,2 ,3 ], [1 ,3 ], [2 ,3 ], [1 ,2 ], [] ]
解:方法一:给的nums都是不同的元素,都没有排序过,返回的list总会包含[],这几点需要注意。
这也是非常典型的用回溯完成的题目。和之前几个需要考虑和为target的或者每个集合里面必须有所有数字的排列来说,其实终止条件比较简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution { public List<List<Integer>> subsets(int [] nums) { List<List<Integer>> result = new ArrayList<>() ; if (nums.length == 0 || nums == null) return result; Arrays . Helper(result , nums , new ArrayList<>() , 0 ); return result; } public void Helper(List<List<Integer>> result , int [] nums , List<Integer> curList , int start ) { result.add(new ArrayList<>(curList)); for(int i = start; i < nums.length; i++) { curList.add(nums[i ] ); Helper(result , nums , curList , i + 1) ; curList.remove(curList.size() - 1 ); } } }
方法二:考虑每一位可以选某个元素或者不选,相当于填空。
Given a collection of integers that might contain duplicates, nums , return all possible subsets (the power set).
Note : The solution set must not contain duplicate subsets.
Example:
1 2 3 4 5 6 7 8 9 10 Input: [1 ,2 ,2 ] Output: [ [2 ], [1 ], [1 ,2 ,2 ], [2 ,2 ], [1 ,2 ], [] ]
解:与78题相比,Input可以有重复元素。具体写法上主要是for里面需要增加循环终止的条件,因为相同的元素只能使用一次,再次使用产生的结果会是重复的。具体做法也和之前一样,排好序之后,当前循环变量(i)不为start之后(条件为i > start或者i!=start都可以),只要 nums[i] == nums[i-1],就continue。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution { public List<List<Integer>> subsetsWithDup(int [] nums ) { List<List<Integer>> result = new ArrayList<>() ; if (nums == null || nums.length == 0 ) return result; Arrays . Helper(result , nums , new ArrayList<>() , 0 ); return result; } public void Helper(List<List<Integer>> result , int [] nums , List<Integer> curList , int start ) { result.add(new ArrayList<>(curList)); for(int i = start; i < nums.length; i++) { if (i > start && nums[i ] == nums[i -1 ] ) continue; curList.add(nums[i ] ); Helper(result , nums , curList , i + 1) ; curList.remove(curList.size() - 1 ); } } }
Given a string s, partition s such that every substring of the partition is a palindrome.
Return all possible palindrome partitioning of s.
Example:
1 2 3 4 5 6 Input : "aab" Output :[ ["aa" ,"b" ], ["a" ,"a" ,"b" ] ]
解:判断是否为回文串的部分可以单独定义成一个函数。一头一尾两个指针扫描,必须相等才能是回文串。利用自增自减简化写法。只有符合要求才放入curList
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution { public List<List<String >> partition(String s) { List<List<String >> result = new ArrayList<>(); backtrack(result, new ArrayList<>(), s, 0 ); return result; } public void backtrack (List<List<String >> result, List<String > curList, String s, int start) if (start == s.length()) result.add(new ArrayList<>(curList)); else { for (int i = start; i < s.length(); i++) { if (isPalindrome(s, start, i)) { curList.add(s.substring(start, i+1 )); backtrack(result, curList, s, i+1 ); curList.remove (curList.size () - 1 ); } } } } public boolean isPalindrome (String s, int begin , int end ) while (begin < end ) if (s.charAt(begin ++) != s.charAt(end --)) return false ; return true ; } }
Given an integer array nums , find the sum of the elements between indices i and j (i ≤ j) , inclusive.
The update(i, val) function modifies nums by updating the element at index i to val .
Example:
1 2 3 4 5 Given nums = [1 , 3 , 5 ] sumRange(0 , 2 ) -> 9 update(1 , 2 ) sumRange(0 , 2 ) -> 8
Note:
The array is only modifiable by the update function.
You may assume the number of calls to update and sumRange function is distributed evenly.
解:简而言之,这道题简直就是为了考线段树(Segment Tree)而出的。这道题非常符合线段树的使用场景,详细可参考这篇文章
参考LeetCode国际站高票代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 class NumArray { class SegmentTreeNode { int start, end ; SegmentTreeNode left, right; int sum; SegmentTreeNode(int start , int end ) { this.start = start; this.end = end ; this.left = null; this.right = null; this.sum = 0 ; } } SegmentTreeNode root = null; public NumArray(int [] nums ) { root = buildTree(nums , 0, nums .length - 1) ; } private SegmentTreeNode buildTree(int [] nums , int start , int end ) { if (start > end ) { return null; } else { SegmentTreeNode ret = new SegmentTreeNode(start , end ) ; if (start == end ) { ret.sum = nums[start ] ; } else { int mid = start + (end - start) / 2 ; ret.left = buildTree(nums , start , mid ) ; ret.right = buildTree(nums , mid + 1, end ) ; ret.sum = ret.left.sum + ret.right.sum; } return ret; } } public void update(int i, int val ) { update(root, i, val ); } void update(SegmentTreeNode root, int pos, int val ) { if (root.start == root.end ) { root.sum = val ; } else { int mid = root.start + (root.end - root.start) / 2 ; if (pos <= mid) { update(root.left, pos, val ); } else { update(root.right, pos, val ); } root.sum = root.left.sum + root.right.sum; } } public int sumRange(int i , int j ) { return sumRange(root , i , j ) ; } public int sumRange(SegmentTreeNode root , int start , int end ) { if (root.end == end && root.start == start) { return root.sum; } else { int mid = root.start + (root.end - root.start) / 2 ; if (end <= mid) { return sumRange(root .left , start , end ) ; } else if (start >= mid+1 ) { return sumRange(root .right , start , end ) ; } else { return sumRange(root .right , mid +1, end ) + sumRange(root .left , start , mid ) ; } } } }
给定一个会议时间安排的数组,每个会议时间都会包括开始和结束的时间 [[s1,e1],[s2,e2],...] (si < ei),为避免会议冲突,同时要考虑充分利用会议室资源,请你计算至少需要多少间会议室,才能满足这些会议安排。
示例 1:
1 2 输入: [[0 , 30 ],[5 , 10 ],[15 , 20 ]] 输出: 2
示例 2:
1 2 输入: [[7 ,10 ],[2 ,4 ]] 输出: 1
解:这道题是252(Meeting rooms)的进阶版,但是这道题做出来就够了,两者思路一样。
我们可以开两个数组,把所有开始时间放到开始时间(startTime)数组,结束时间放到结束时间(endTime)数组,然后把两个数组排序。排序之后虽然两个数组的开始时间和结束时间不对应了,但是不影响最后数值结果。
为什么?可以用一个房间出入的例子。一个房间可能有A、B、C出入房间,但是我们不需要直接特定时间是谁进和出房间,只需要管人数就行了。
我们不在乎某一个会议几点开始和几点结束,我们只关心排好序的数组中是否有冲突。